Adopting a functional paradigm with Jupyter Notebooks

In case you don’t know, a Jupyter Notebook is a webpage running along with some REPL (Read Eval Print Loop) — most often Python — where you can interact with the program and write a document as you go. It supports Markdown and LaTex-like mathematical annotations, which help to build good-looking documents. Jupyter Notebook is a tool widely used by data analysts, engineers, scientists, and others. It is popular because Jupyter makes development interactive: You can run some code, get immediate feedback, and easily turn it into a shareable document.
However, it’s hard to strike a balance between lightweight and organized code. Notebooks tend to be a place of chaos and random behavior, but don’t give up! It’s possible to do better.
Limits of most notebooks
From my experience with Notebooks, I found three main limits: They are error-prone. They are hard to follow. Taking the code to production is “hell”.
1. They are error-prone
Commonly, most of the variables and functions are kept in the main scope. Like the example below:
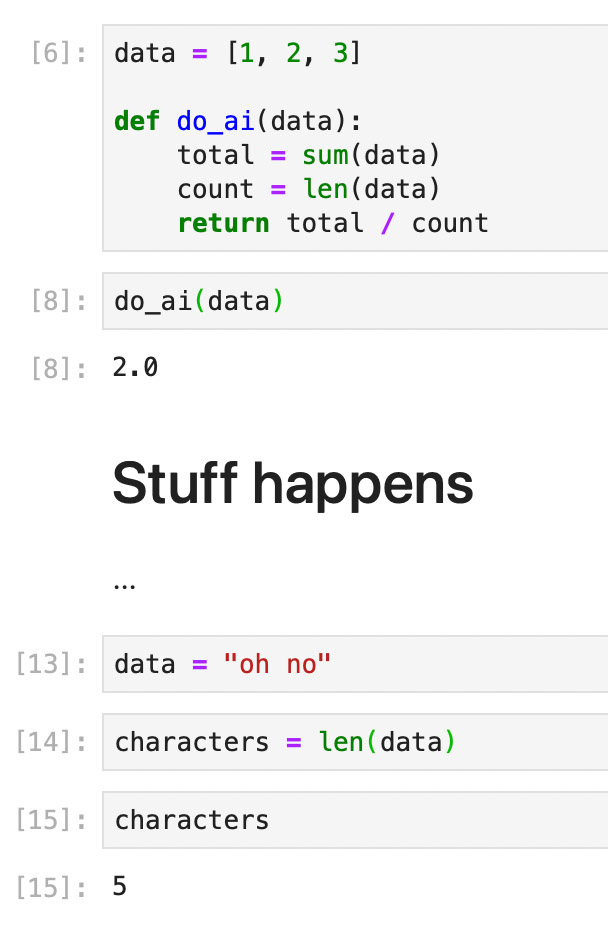
What happens when we run cell [8] again? It would fail because the variable data has changed; it was mutated.
It’s fine most of the time, but it can lead to subtle bugs or incomprehension. First: what does data mean in this context? It’s the function’s argument, but it was also defined in the main scope.
I read many Notebooks where the data is defined in the main scope and it’s accessed or mutated from inside functions without it being declared as an argument, like the example below:
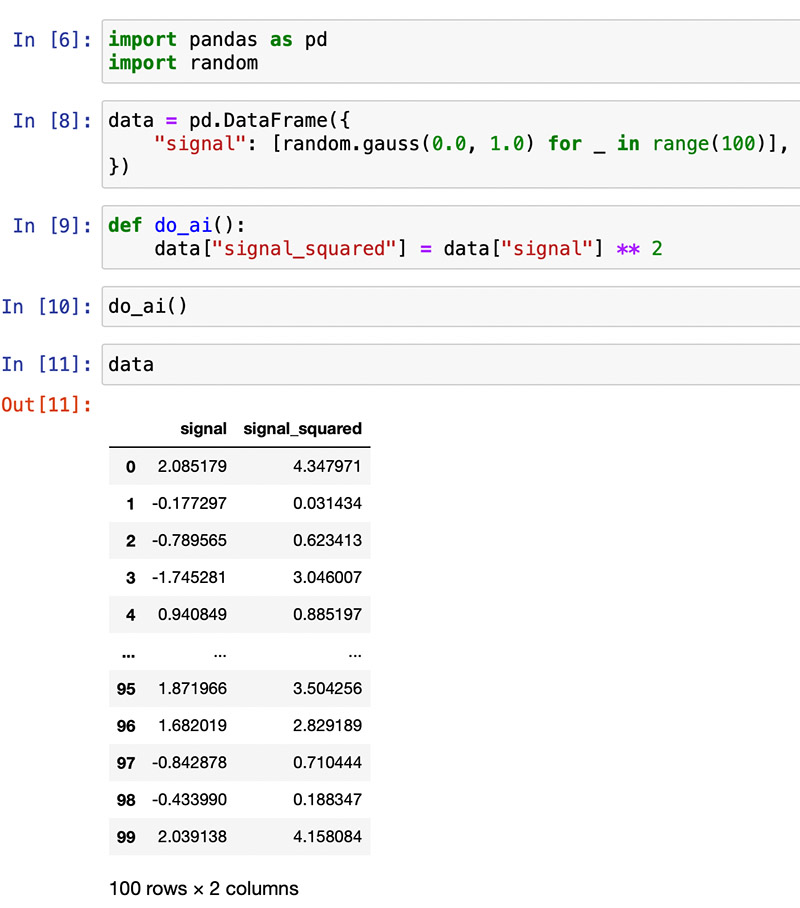
But what if ‘data’ changes? What if it becomes a string?
This can lead to subtle errors that might manifest after you have shared your promising results with your team. I hate when that happens.
Also, as you rewrite or delete cells, you might lose some critical parts of your pipeline. It can be head-scratching the next day when you run your cells with a fresh REPL and find pieces are missing.
2. They are hard to follow
While it can be clear as you are writing it, it may be obscure for other readers. Don’t be egotistical because the «other» can be you tomorrow or in three months when you really want to conduct this analysis again.
The reason is simple: it’s cognitive load.
As you are writing it, it stays warm in your head. You already loaded it in your brain’s RAM and you don’t have issues working with it. So «workflows» like launching cell one, then cell five, then cell one again work with warm memories but are atrocious when you completely forgot what you were doing.
New readers will have to «load». If it’s a big spaghetti, you ask them to load a lot at once, which consumes a lot of energy and attention. And attention is limited.
Here is an extract of a «hot» Notebook I found on Kaggle:
It’s only an extract; it goes on for a while. When writing things like that, you ask your readers to remember the state of a mutable object, which requires a high cognitive load (it’s a mess).
Plus, if it’s stateful, who knows what will happen if you relaunch it (provided the reading doesn’t happen again)?
3. Going to production is “hell”
At the end of the day, you will want to turn your efforts into something useful. That could be a report if it’s an analysis or a machine learning pipeline if you were training a model. Most of the time, it’s almost equivalent to starting over.
You cannot take the above snippet and go to town. Production has different requirements. You want tests, and you want to expose some variables so that you can – for instance – conduct the same analysis on a different day.
If everything is stateful and in the main scope, you will have a hard time doing that.
Those are simple, seemingly harmless things that I admit I have been doing for a while. But the costs of this are high. Hopefully, we can apply simple rules of functional programming to solve all of that and more!
Functional programming tips
Paradigm
Functional programming is a programming paradigm in which you dissociate the code and the data. You deal with (mostly) pure functions, meaning functions that don’t modify their inputs nor interact with the outside world.
This may appear odd, but you will see it has simple implications, especially in Python, which offers flexibility.
If you take our do_machine_learning function from earlier, it’s pure. It doesn’t interact with the outside world, nor does it modify its inputs. do_ai on the other hand isn’t pure because it modifies a variable from the main scope.
If a function is pure, calling it with some input will always return the same output. That reduces cognitive load. I don’t have to remember much besides what the function is doing.
Application
Applying functional programming to our context is simple. Decompose things into functions. Remember this Jupyter Notebook from Kaggle I mentioned earlier? The blocks below those comments could be almost extracted one-to-one into functions with the comment as the function’s name. It would improve clarity because the execution would be bounded. It would be clear what the inputs and computations are.
Additionally, by using pandas functions without inplace=True (which — by the way — will be deprecated) we get pure functions:

Each function does only one thing. The input is clearly stated, and it’s not mutated. We return a transformation of the input.
Now, we could be getting the output of it all by composing those functions, either like a savage:
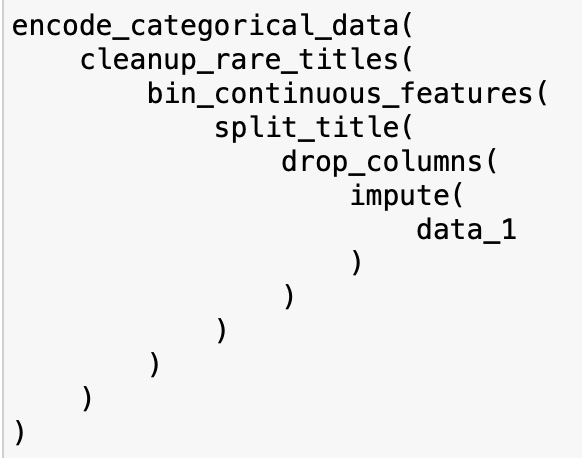
Or using Pandas piping function:
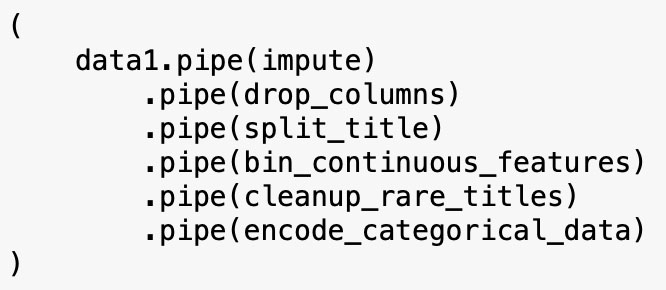
Or with a more general approach using reduce:
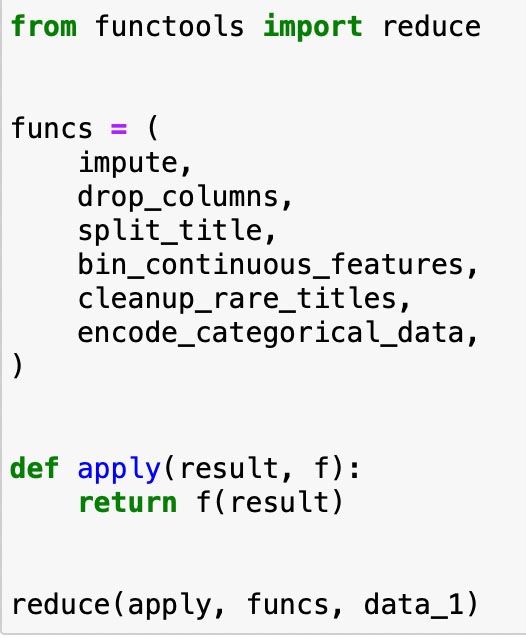
Conclusion
By adopting a functional paradigm in Jupyter Notebook, you can break your code down into functions.
It’s less error-prone because each step does exactly one thing. If you have a bug in a function, fix it, rerun the cell, and things are fine.
It’s easier to follow because your steps are clearly identified, named, and state their inputs and outputs.
Also, they are easier to test. You can test each one independently without messing around with a big spaghetti in the main scope. So, going to production is easier.
It came at the cost of little overhead (it’s only functions!) – and, guess what: it has more impact than just cutting the time you spend working on your Notebooks, reading your colleagues’ work, and taking all of that to production.
Since you broke things down into independent steps, they can easily be reused in other projects to do the same thing. You can test them once and reuse them, and compose them all across your projects! The more you do, the less you have to do. It compounds.